My Synthesis of Analytics
Having worked in analytics across various settings—from roles embedded within business units to centralized product analytics organizations, spanning an online marketplace, a big-box retailer, a D2C brand, and from the largest employer in the US to a 200-employee startup—I have observed some common patterns in analytical needs. This post aims to synthesize those observations.
The figure below illustrates the placement of analytics in relation to stakeholders, partners, and similar roles, as well as the tools, activities, and output formats used in analytics.
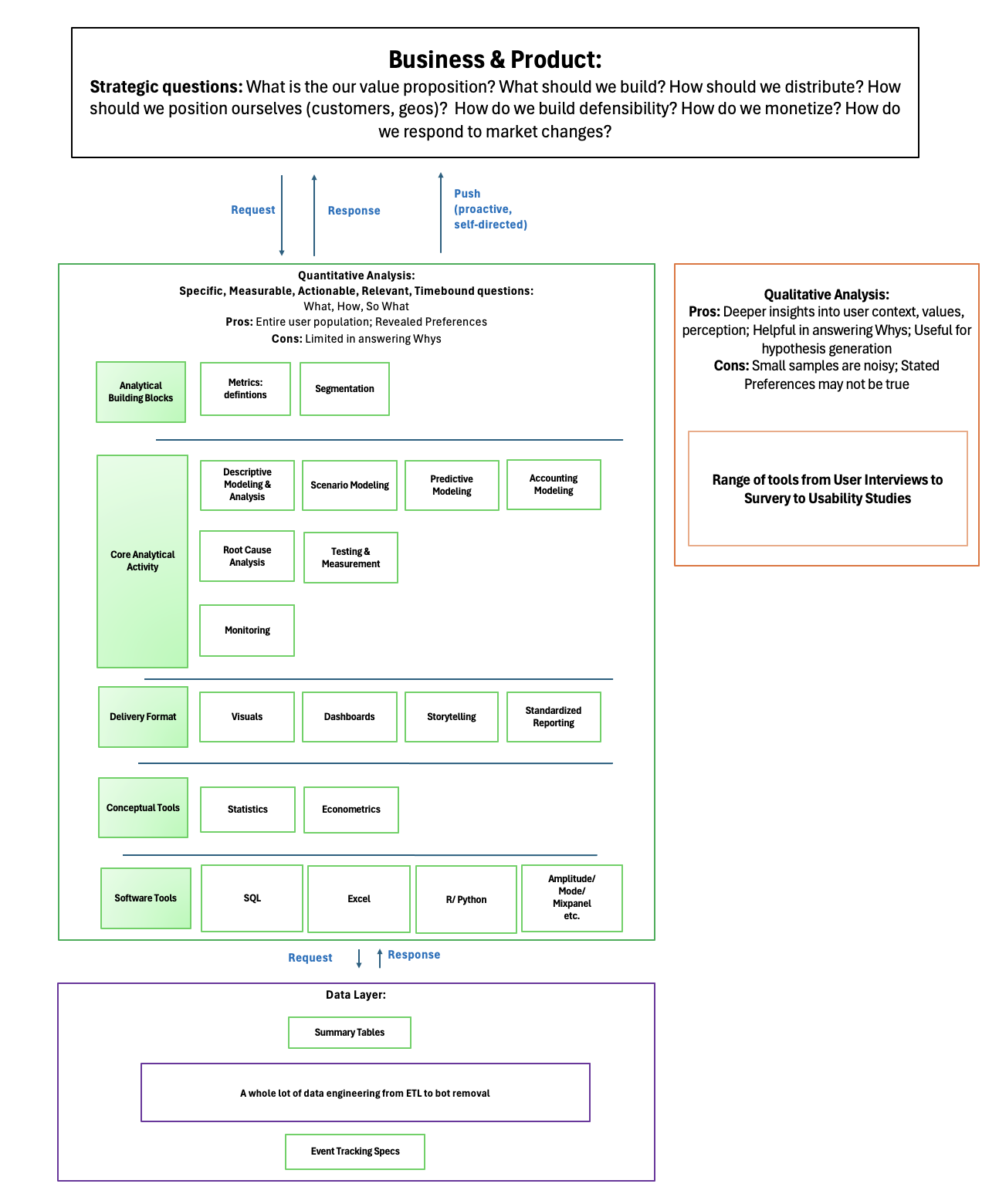
In the following discussion, I will not focus on the conceptual and software tools of analytics. Instead, I will discuss the analytical paradigms I label as the Request-Response model and the Push model; the outputs of analysts; the key questions to ask requestors under the Request-Response model; and the importance of conducting meta-analyses. Note that I have placed the outputs of analysts in several buckets. However, these buckets are not mutually exclusive—some activities, such as metrics definition or segmentation, may stand alone as outputs for a meeting, or they may serve as inputs to other analytical activities, like Descriptive Modeling. The categorization reflects my impressionistic view, based on the time and mental energy devoted to various analytical activities in my experience.
The Two Paradigms:
As mentioned, I think of analytical efforts through the lens of two paradigms:
1.Request-Response Model:
In this paradigm, analysts respond to requests from business or product teams. These requests range from simple data pulls, such as descriptive statistics of the previous week’s sales, to more complex questions, like how sellers’ listing behavior in a marketplace changed in response to past price changes. This is the most common mode of analytical activity.
2. Push Model:
In contrast, the Push Model involves analysts performing self-directed analyses to offer insights they believe will directly drive business and customer value or provide a deeper understanding of customers, regions, products, and the overall business.
For example, this Lyft Engineering article describes how the Experimentation team identified unaligned initiatives across the business. In one case, a team offered a $10 coupon to acquire a ride, while another team was losing $5 for each ride, leading to a net loss for Lyft with no change in rides. Similarly, at DoorDash, the Analytics team defined a common currency for relating different metrics—such as how $1 in lower price or 1 minute of delivery time saving translates to order volumes—thereby facilitating tradeoff decisions between marketing and logistics investments. Faire offers another example, where the team developed ROI equations to fully capture marketplace dynamics, including the customer acquisition cost (CAC) of both customers and the suppliers they purchase from.
In my own experience (elaborated in the Descriptive Modeling and Analysis: Analysis of Dynamics section), a standard product health monitoring activity for the Favorites page of an online grocery retailer led to self-directed analysis that revealed inefficiencies in how customers were building their baskets. While 80% of returning customer baskets contained items already on their Favorites page, customers were primarily adding those items from Search or Browse instead. This insight led to further exploration on basket building patterns, prompting hypotheses and experiments to streamline the process and improve customer loyalty.
In a complex business with many moving parts, it is often impossible to have visibility into or even recognize certain problems and opportunities without the benefit of a particular vantage point. The Push model is effective when analysts can cut across products and regions through either direct analytical experience or knowledge sharing to identify new questions. In some ways, this is reminiscent of the aggregated data model leveraged by ad networks or private labels.
The Push model also works when analysts adopt a business unit (BU) or product management (PM) mindset. This is akin to having customer empathy—in this case, the customers for analysts are the BUs and PMs. Thinking like a BU or PM not only helps anticipate requests but also enables the generation of new, valuable questions that BUs or PMs may not have considered due to bandwidth limitations or blind spots.
Another way to articulate the two approaches might be as inbound vs. outbound models. In terms of volume, most analytical efforts operate within the Request-Response model. However, in terms of total impact, the share may not be as skewed since the Push model has the potential to offer higher leverage output, even if such outputs are less frequent. Additionally, both paradigms may entail high-effort, high-complexity analyses.
Requests of Requests and Analysis of Analysis:
Scoping:
As noted previously, most analytical work falls within the Request-Response model. However, there is a distinction between responding to requests and engaging in “reactive” work. The scenario described in this post exemplifies the latter: “Very often, data scientists receive what I call ‘data Siri questions’ like ‘How many active users do we have?’ Once you pull that stat, you often get follow-up questions (e.g., geographic breakdown of the users, etc.). Before you know it, what seemed to be a 5-minute ad hoc data pull turns into 100 seemingly disconnected data questions.”
The post then suggests a solution: “The most efficient way to deal with these situations is to start from the ‘why.’ When you understand that the PMs are trying to launch a new feature on iOS and need data to decide which countries to prioritize based on engagement, you can suggest the most insightful data cuts to answer that question. Or, if you dig even one level deeper, you might question whether engagement is the right metric to prioritize countries.”
I believe this solution is spot on. It highlights the importance of establishing scoping documents, which involves asking questions about the requests.
Without careful management, ad hoc requests can easily expand in scope, become repetitive and ineffective, and even lead to analyst burnout. This problem is particularly pronounced when multiple stakeholders are assigned to one analyst, as each stakeholder, understandably focused on their own goals, lacks visibility into the requests of others.
Additionally, as highlighted in this post from Faire, without proper scoping, “Sometimes we would spend time exploring an open question, only to realize we didn’t have the right data to answer it — or that we hadn’t actually answered the original question.”
I believe scoping documents should cover the following questions:
- What problem or objective is this analysis addressing?
- How does solving the problem or meeting the objective benefit the business and/or customers?
- When is this information needed? If urgent, what is the reason?
- What will be the next steps based on this analysis? What actions will map to various outcomes?
- Which analytical activities are involved? E.g., metric definition, modeling, analysis of dynamics.
- Are there similar analyses that can be leveraged?
- What should the delivery format be? E.g., a dashboard, a report with a specific format, explanatory storytelling. Can we outline the delivery and work backwards? Can we create visuals with dummy data first?
- Do we have all the required data, or is data collection or instrumentation needed?
- What potential blockers might affect this analysis?
- Which teams need to be involved to complete this analysis?
The specific questions and their application depend on the context. However, questions 1-4 help prioritize and rank requests. Question 4 also aids in anticipating iterative requests. Questions 5 and 6 help identify reusable patterns from previous analyses. Question 7 sets boundaries by “working backwards.” Questions 8-10 help anticipate issues that may delay the output.
Meta-analysis:
While a scoping document enhances efficiency for individual analyses, conducting a meta-analysis of these analyses can reveal recurring patterns and improve effectiveness on a broader scale. To that effect, it may be useful to update the scoping document with information such as:
- What was the final status of the analysis: conclusive, inconclusive, deprioritized, or canceled?
- What were the blockers, if any?
- What further clarifications were needed that were not considered initially?
- What were the key takeaways of the analysis?
- Were any recommendations made? Were they adopted? If not, why not?
- How long did the analysis take, i.e., the days elapsed between the request and the final status?
A meta-analysis based on this updated information would help us identify the most requested types of analyses, common blockers, and the time spent on lost effort. It can also help new team members get up to speed quickly, provide access to a repository of past ideas that may be more applicable to new contexts, and identify patterns that enable push/self-directed analysis.
Analytical Activity and Delivery:
In structuring the Analytical Activities, I’ve categorized them into three distinct areas: Building Blocks, Core Activity, and Delivery Format. The Building Blocks form the essential groundwork for any analysis. These activities—such as defining metrics and segmenting information—are critical because they ensure that subsequent analysis is built on a solid foundation. While distinct from Core Activities, which focus on tasks more directly leveraged by the business, the Building Blocks are integral to the analytical process and, in some contexts, can even stand alone as primary deliverables.
Moving into the Core Activity, this section covers the analytical tasks that are more traditionally expected—generating insights, creating models, and formulating recommendations. These activities are the core of analysis and play a pivotal role in influencing decision-making, as demonstrated in the case studies and examples included. Finally, the Delivery Format addresses how these insights and recommendations are communicated to stakeholders. The effectiveness of this communication often determines whether the analysis will drive actionable outcomes or fade into the background.
Additionally, this section includes some activities related to the Data Layer. I have included these because, once again, they represent critical work that consumes a significant amount of an analyst’s time.
Analytical Building Blocks
1. Metrics -
Metrics are a quantitative description of either the outcome a product or business aims to achieve or the milestones, trade-offs, or inputs along the way. As highlighted in the post Common Mistakes In Defining Metrics, “Your metrics are a reflection of your strategy. They help answer, is the strategy working? Metrics without strategy is like looking at a bunch of random numbers.”
There are views that, “the main KPIs definitions should come from PMs, as they know their product best. Analysts help to adjust its definition and formulas based on available data and make it accessible for monitoring and reporting.” I think that while BUs and PMs are responsible for articulating their goals and the trade-offs they envision, and ultimately for signing off on the metrics, the definition may not necessarily originate from them. Their responsibilities might not expose them to certain nuances in metrics.
To save time and effort on both sides, the analyst should pressure test whether the metric is a vanity metric or if it is an input metric that can actually be moved as opposed to an output metric. Or for instance, if a Business Unit (BU) or Product Manager (PM) requests a ratio metric like DAU/MAU, the analyst should consider whether a histogram might be more insightful. Similarly, if the BU or PM asks for simple churn numbers, the analyst should evaluate whether these numbers could lead to underestimation or if they represent a lagging indicator, such as revenue churn, instead of a more useful leading indicator like user churn. When defining metrics for an A/B test, the analyst can suggest proxy metrics that might allow the test to be more conclusive or conclude faster while still capturing the necessary information.
{kind=link}
It may not be practical to go through an exhaustive checklist for every single metric definition. Instead, this is a reminder of the common pitfalls associated with metrics. The key is to find a balance between thorough upfront thinking and avoiding endless iterations.
2. Segmentation -
Segmentation in business and product analysis typically involves grouping users at both the overall business level and within various programs. The goal is to identify “like” users to address common problems they face or create.
Different teams, focusing on different problems and having access to different levers, may require unique segmentation approaches.
For example, in the Seller Experience team of an online marketplace, segmentation might be based on factors such as tenure, trailing 12-month GMV, listing frequency, and primary listing category. A new seller selling clothing may need different support and incentives compared to a veteran seller who makes $1M per year selling automotive parts. The former might need listing flow guidance and a $10 Sell To Buy coupon, while the latter might benefit from a bulk listing tool and volume-based discounts.
In contrast, the Seller Trust and Safety team, which aims to reduce poor buyer experiences, might segment sellers by “quality” using metrics like buyer ratings, percentage of orders not delivered on time, and percentage of items not meeting expected conditions. High-quality sellers might receive a boost in search rankings and special badges, while low-quality sellers might face listing limits.
Segmentation can range from simple quantile-based grouping to complex n-dimensional clustering on composite metrics. Ultimately, it is crucial to base segmentation on customer and business problems and ensure that segments are interpretable and actionable. In other words, the process should begin by identifying the problems we want to solve and the goals we want to achieve through segmentation. Then, we can determine the most useful way of classification. Such an approach would help avoid the type of common pitfalls that companies including DoorDash and Airbnb have encountered.
Core Analytical Activity
1. Descriptive Modeling and Analysis (includes Exploratory and Time Based Analysis) -
Descriptive modeling involves creating a mathematical representation of a system based on both real inputs and informed assumptions, essentially describing a product or business as an equation. These models help us understand how different components of the system interact, and they also lay the groundwork for Scenario Modeling, as described in the next section.
Below is an example of a growth equation from Amazon:
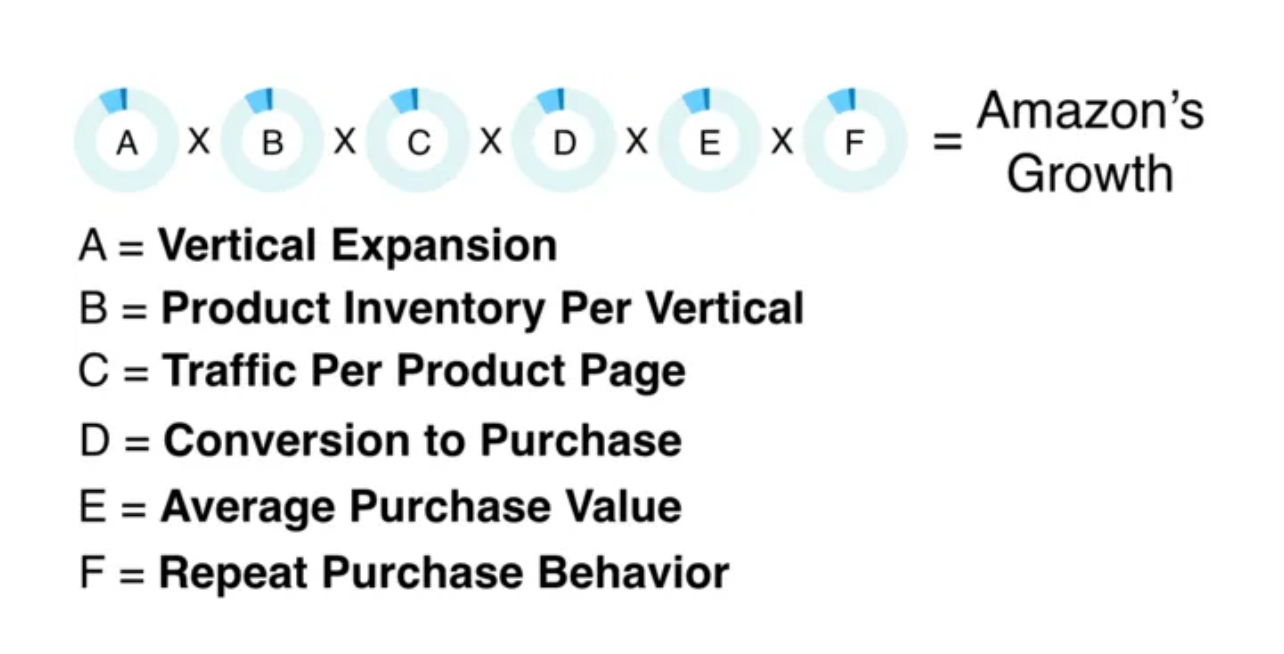
Image Source: Indispensable Growth Frameworks from My Years at Facebook, Twitter and Wealthfront
and below is another one from Google:
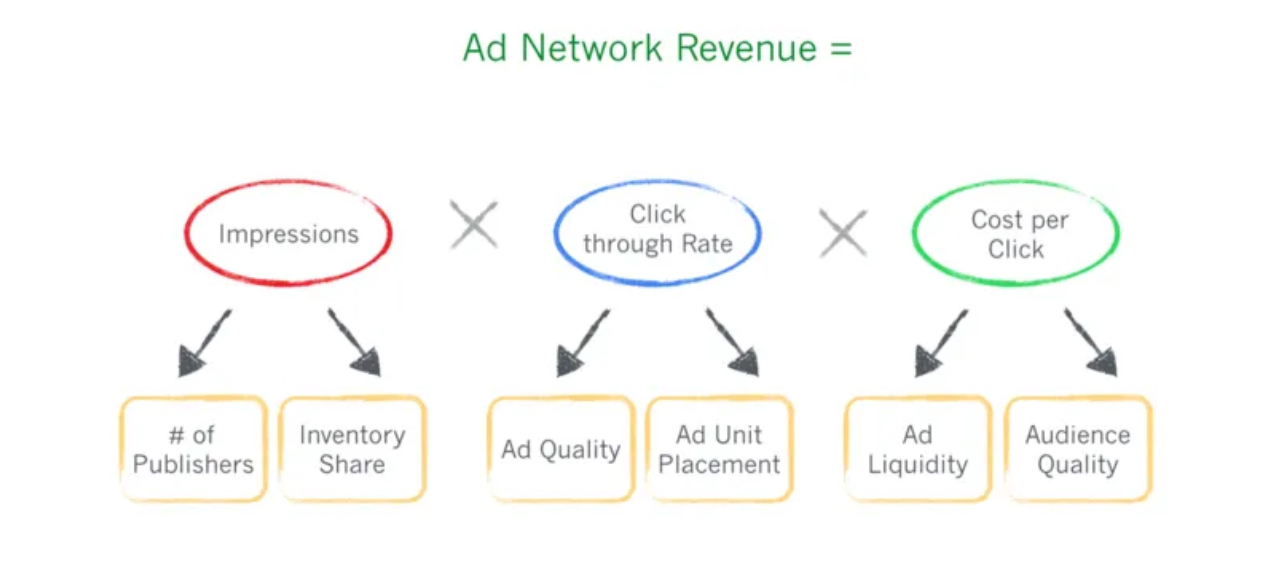
Image Source: Startup Best Practices 17 — Strategic Planning Using Your Startup’s Fundamental Equation
Descriptive analysis, grounded in these models, provides insights into how things were and are. Such analysis helps in understanding the “lay of the land.”
Examples of descriptive analytics include: weekly business reviews, year-over-year sales reports, as well the case study here (which starts with Descriptive Analysis and then moves on to Scenario Modeling).
Exploratory analysis :
Exploratory analysis is a form of descriptive analysis. In such analyses, it can be tempting to dive straight into the data to extract statistics like mean, median, distributions, and correlations. However, it’s generally more effective to start with a clear list of questions and hypotheses. This approach helps manage the scope of the analysis and ensures that the findings are both interpretable and actionable. While raw statistics are valuable for building algorithmic models, in the context of business decision-making, the focus should be on generating insights that can directly inform actions.
Analysis of Dynamics :
A significant aspect of descriptive analysis is what I call the “Analysis of Dynamics”. This involves examining changes over time, such as in cohort analysis, or across different stages, as seen in funnel analysis, growth loops, or path analysis. These analyses are not limited to user behavior; they can also apply to product health, inventory levels, and other critical business aspects.
To illustrate the practical application of descriptive and dynamic analysis, consider the following case study:
Case Study: Analyzing the Favorites Page and Basket Building
This case study demonstrates how descriptive and dynamic analyses were used to uncover issues with the Favorites page and understand customer behavior in basket building.
Favorites Page Analysis:
The Favorites page stored items that customers explicitly favorited and all items from any past purchases. However, the product health metrics showed low overall adoption of the page (i.e., add-to-carts from that page), especially among longer-tenured customers.
Data indicated that 80% of the items in returning customer baskets were already on their Favorites page before their most recent purchase, yet these items were mostly added to the cart from the Search or Browse pages instead. In theory, the Favorites page should serve as a one-stop shop for 80% of basket items, promoting efficiency, but customers were not using it that way.
Further analysis revealed a clear turning point in Favorites page adoption when the number of items exceeded the first page. This insight led to hypotheses that the Favorites page might be too cluttered, sparking both backend (e.g., ranking items by frequency instead of recency) and frontend experiments (e.g., grouping items into category modules similar to those on the Browse page).
Time to Build Basket Analysis:
The analysis of the Favorites page also prompted thoughts about the efficiency of sitewide basket building. A subsequent analysis explored how quickly returning customers familiar with the site build their baskets. It was found that most returning customers build their baskets in about four sessions over a little more than a week, spending about 10 minutes per session. Since 80% of the items in the baskets were present in prior orders, it appears that customers add the same items on a recurring basis as the items run out or as the customers remember. This analysis led to discussions about features that could enable customers to build their baskets faster, potentially saving them time and enhancing customer loyalty vs. focusing on upsell and cross-sell opportunities in each visit, which might increase average order value (AOV).
2. Scenario Modeling (i.e. sizing opportunities and impacts) -
While descriptive modeling shows how things were and are, scenario modeling helps us understand how things could be under various conditions—this is the classic “what-if” analysis. Scenario modeling can build on top of existing descriptive models by tweaking model parameter values or introducing new parameters. When dealing with new features, products, or initiatives, scenario modeling may first require building a new descriptive model first. This type of analysis is often used to estimate outcomes such as ROI or margins:
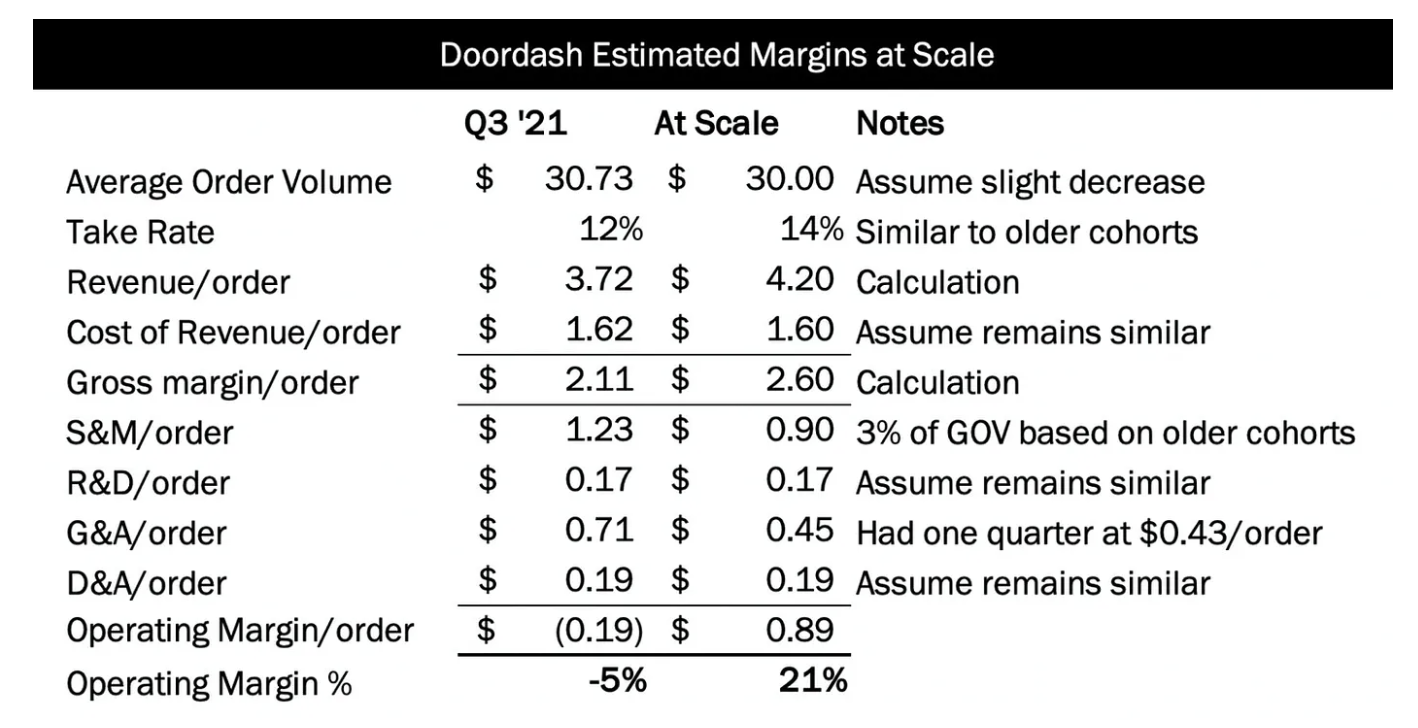
Image Source: Doordash and Profitable Food Delivery - Tanay’s Newsletter
It can also be used for estimating how changes in retention impact acquisition:
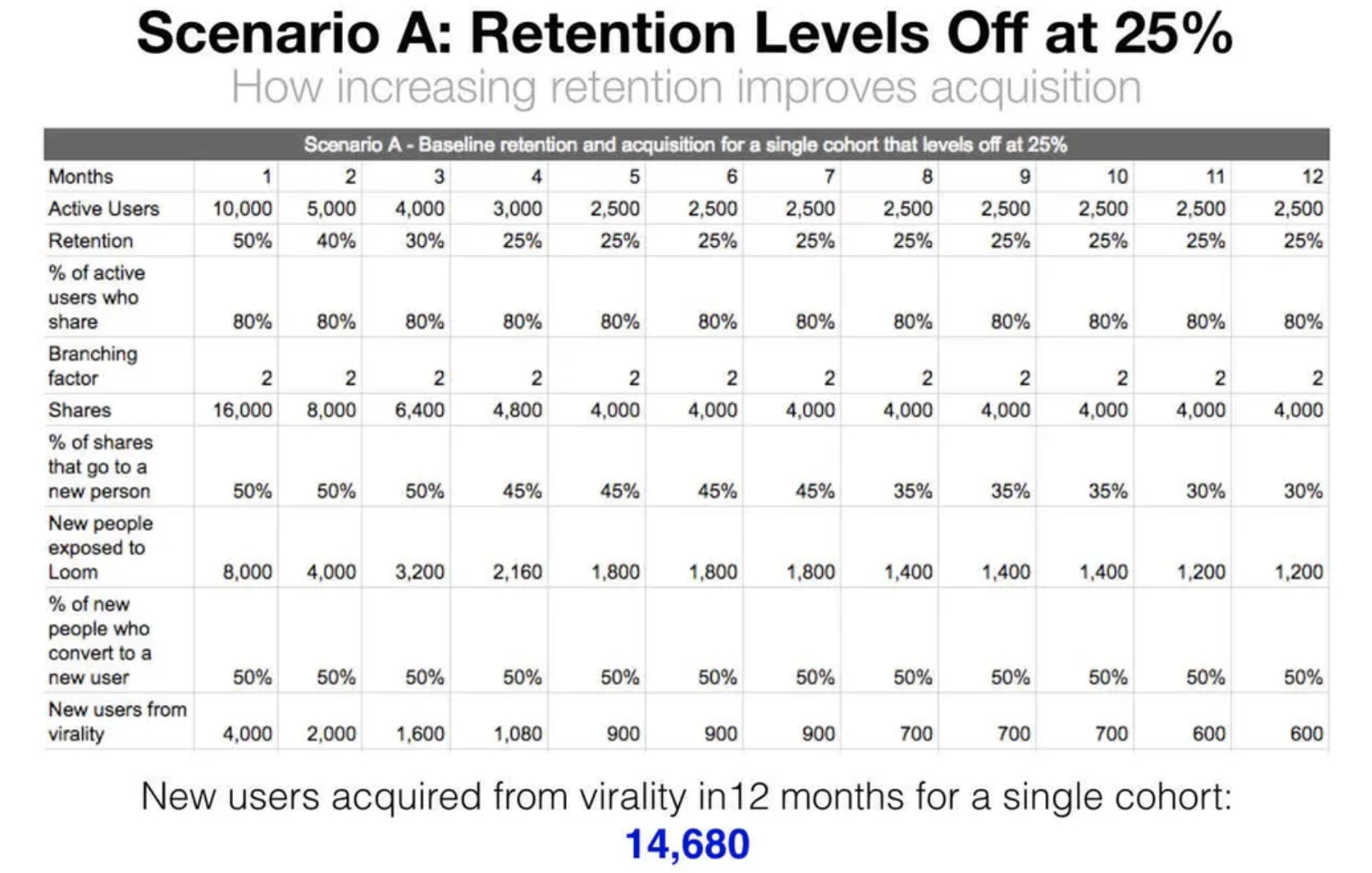
Image Source: The One Growth Metric that Moves Acquisition, Monetization, and …
A particularly sophisticated example of Scenario Modeling is: Lyft Data Science team’s marketplace simulator.
3. Predictive Modeling -
While Scenario Modeling helps us understand how things could be under various conditions, Predictive Modeling tells us how things are likely to be, based on past and present information. Predictive modeling involves extrapolating trends to make forecasts, such as predicting weekly or monthly usage metrics:
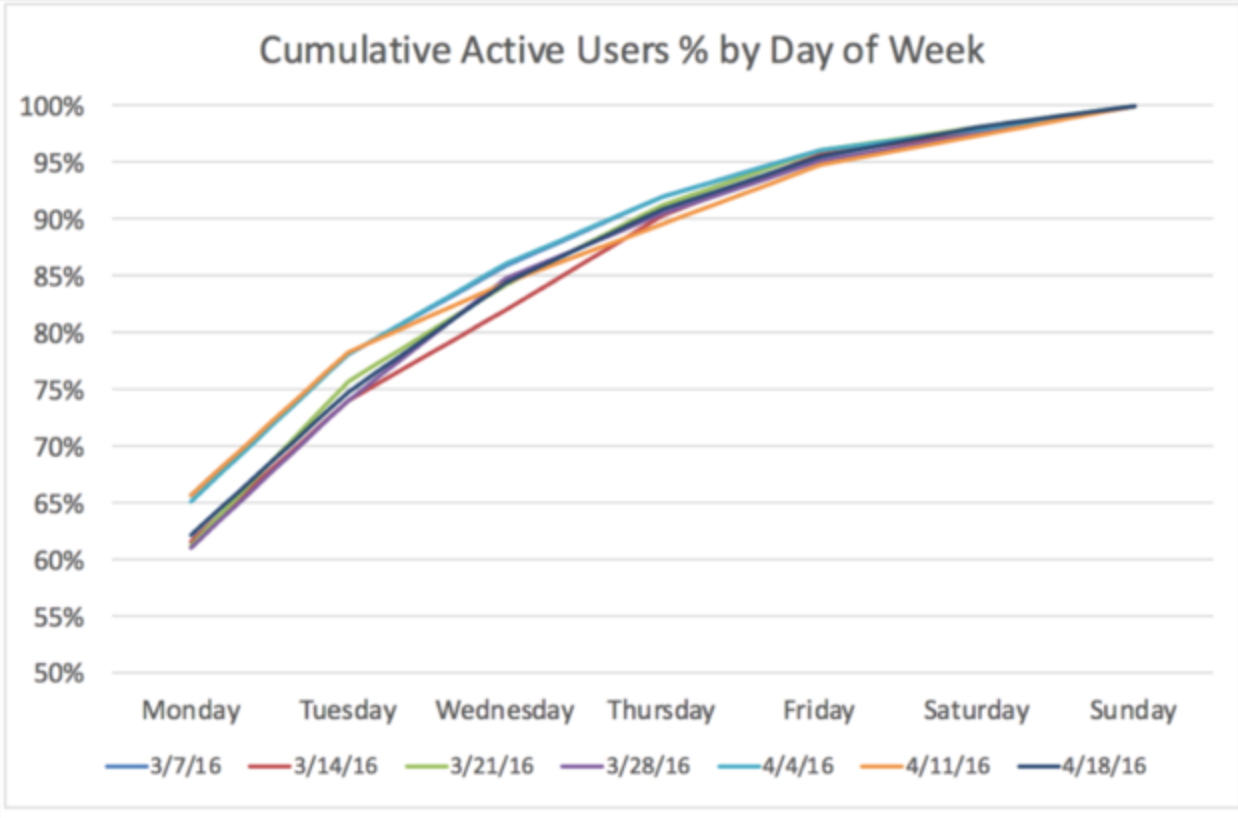

Image Source: How To Predict Your Weekly or Monthly Usage Metrics - Brian Balfour
It also includes applications like establishing customer lifetime value (LTV) or predicting the likelihood of specific events, such as a user churning.
4. Accounting models -
Accounting models involve recording and summarizing metrics based on predefined rules. Unlike models that describe how things were and are, how they could be, or how they are likely to be, accounting models tell us how things should be. A key example is attribution modeling, which assigns credit in multitouch marketing campaigns.
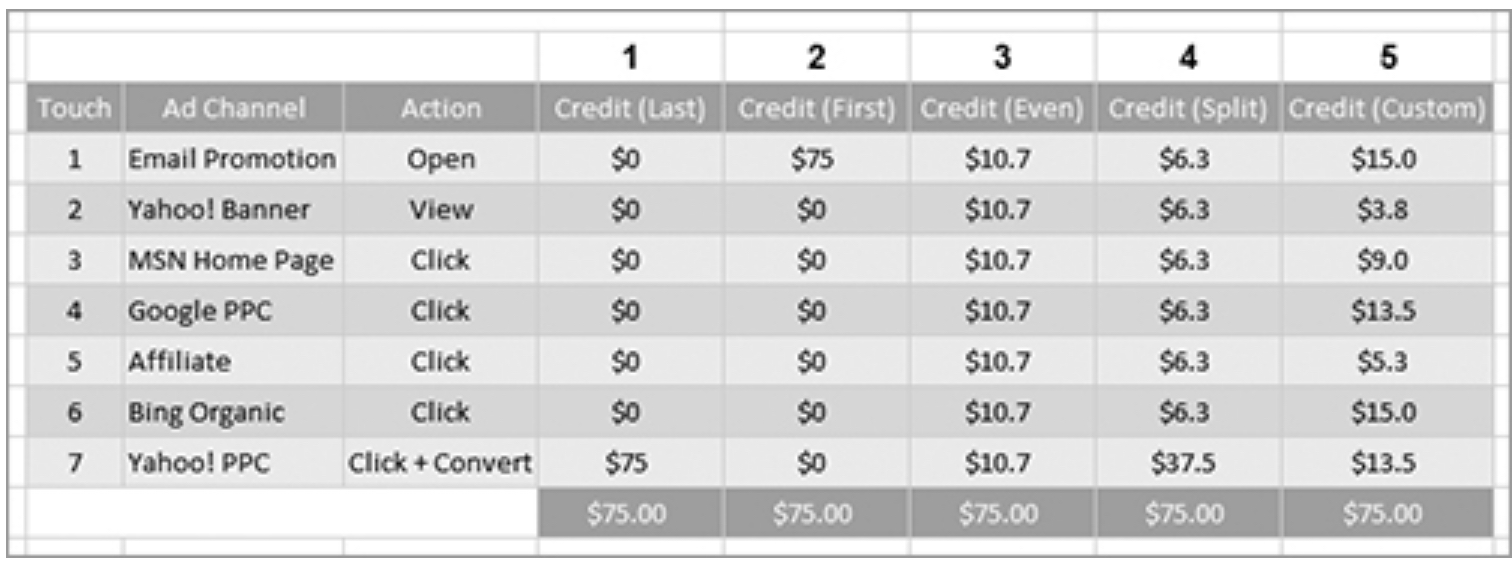
Image Source: Web Analytics 2.0 by Avinash Kaushik
As cited in Web Analytics 2.0:
“In a multitouch scenario, it is impossible to know the influence or impact each touch has on the customer. Without that information, you are going to use your understanding of your business, or even your best guess, for how to attribute credit.”
Kaushik further explains that:
“Attribution often comes down to a qualitative judgment. Each person’s answer might be different. The reason marketers, advertisers, publishers, and HiPPOs will fight to the death on this issue is quite simple: each wants a piece of the action, and each wants credit for the conversion (if not all, then some of it) so they can stay in business (or get promoted).”
While analysts can build and maintain these models in spreadsheets, the rules and principles behind them should come from the business units (BUs) and product managers (PMs), aligned with the overall philosophy of the business.
5.Root Cause Analysis (RCA) – Also Known as Diagnostic Analytics (Including Data Validation/Reconciliation) -
Root Cause Analysis (RCA) is typically conducted in response to an issue or an unexpected data trend. The unexpected trend may be due to data errors such as missing, stale, or duplicate data, or due to data interpretation issues. For example, one challenge in data interpretation is Simpson’s Paradox, where trends that appear in different groups of data disappear or reverse when these groups are combined. Another example comes from ShopKick, where a 20%-30% expected increase in a metric due to geofenced notifications only resulted in a 3% increase. A detailed analysis revealed that the impact was significant among new users who joined after the experiment started, but the overall metric was diluted by the large share of existing users whose habits were unresponsive to the product change. This highlights the importance of using segmented rather than blended metrics. However, there is also an argument for a blended view of metrics, as illustrated by the Will Rogers phenomenon.
To further illustrate the application of RCA—this time triggered by an issue—consider the following case study:
Case Study: Drop in Transactions of an Online Grocery Site
Issue:
A significant drop in transactions was observed on a specific day, while up-funnel metrics remained normal until the “Proceed to Checkout” button click on the View Cart page. At this point, users either left the checkout page or exited the site altogether. It was not possible to determine which users were driving the incremental drop-offs.

Approach:
Several factors could result in an increase in checkout drop-offs. By considering the user experience, the following potential causes were hypothesized:
- UX Changes: There may have been changes on the View Cart page impacting specific user segments.
- Errors on the View Cart Page: Issues such as the inability to fetch cart data or load specific components.
- View Cart Page Load Delays: Delays specific to certain platforms or regions may prompt users to abandon their carts.
- Changes in User Expectations: Changes in item availability, price, fees, or promotion expiration between adding items to the cart and proceeding to checkout.
The challenge in RCA is the numerous plausible sources of error, requiring an exhaustive process of elimination until the root cause is identified.
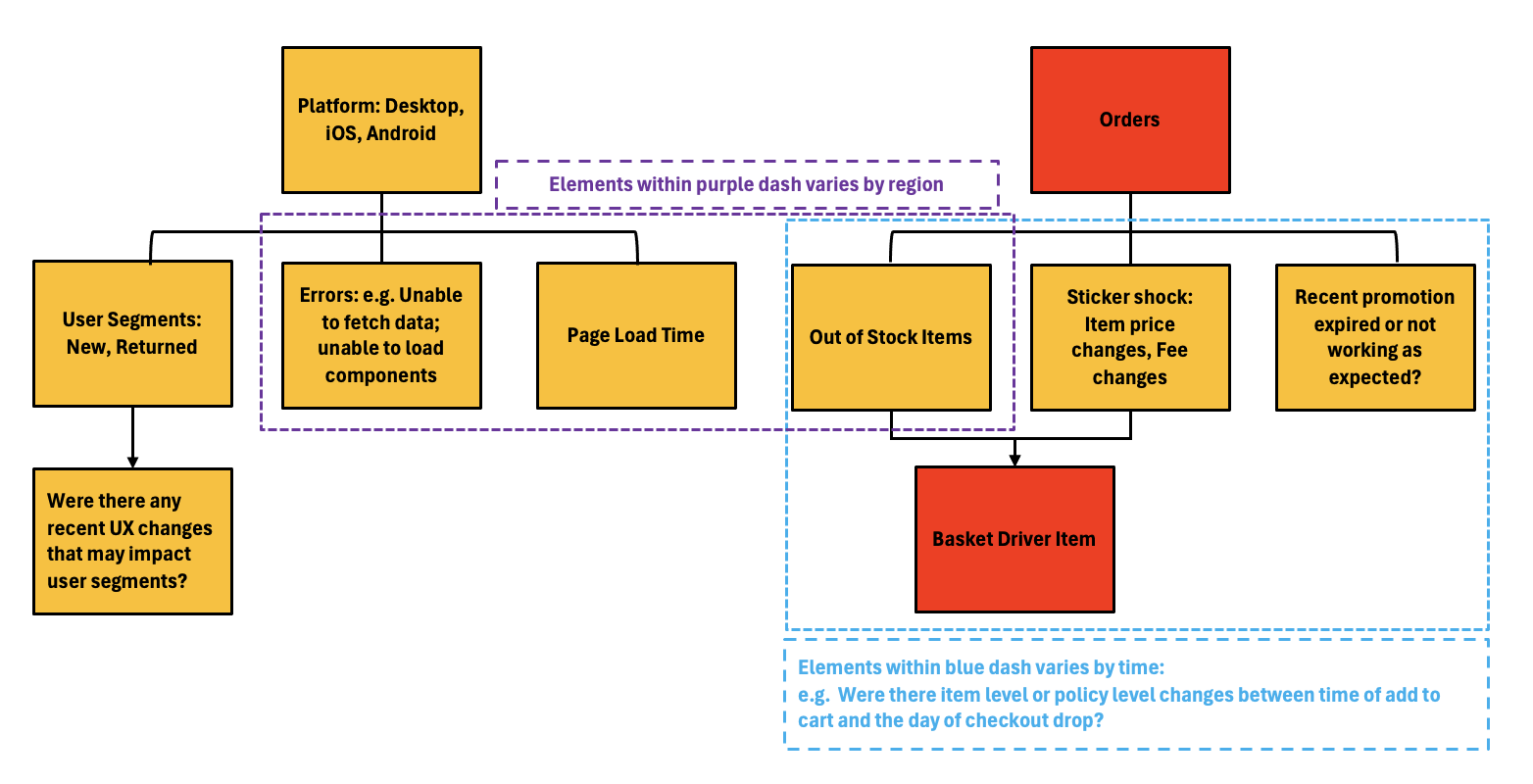
Conclusion:
In this case, the culprit was the unavailability of basket driver items (e.g., milk, eggs) from a particular high-volume store. These items were in stock when added to the cart but went out of stock before the checkout day. This was identified by examining order-level data by region, flagged by out-of-stock status and specific basket driver items.
The issue was subtle because online grocery baskets are generally built over a span of a week. Users added basket driver items when they were in stock, but these items were out of stock when users proceeded to checkout. Although stores were aware of the out-of-stock status, they did not realize the impact on eCommerce orders. The absence of such items reduces Average Order Value (AOV) for in-store customers who might still buy other items, but for online customers, it leads to an order loss due to different dynamics, such as switching costs and minimum AOV for free shipping.
Recommendations:
- Email Affected Users: Offer substitute items and possibly an incentive (e.g., a coupon) to compensate for the bad user experience.
- Data Integration: Incorporate online add-to-cart and build-a-basket data for better store inventory planning.
- Substitute Item Module: Implement a module on the View Cart page to suggest substitute items when items go out of stock.
It is important to note that RCAs may be inconclusive when small issues across various aspects of the product or business add up to a larger problem. This is akin to a “death by a thousand papercuts” scenario, where minor issues collectively cause significant damage. Alternatively, the sum of problems may be greater than the parts due to interaction terms. For example, a combination of data fetching errors, increased page load times, and basket driver items going out of stock can create a significant impact. Even if each issue alone is too small to be measurable, they can get lost in the noise of daily variability but together can cause a substantial problem.
Another challenge of RCA is the need to compare data against a baseline, often a forecast based on past data. This introduces uncertainty over whether the problem lies in the baseline expectations or the actual outcomes.
6. Test/ Measurement design and execution -
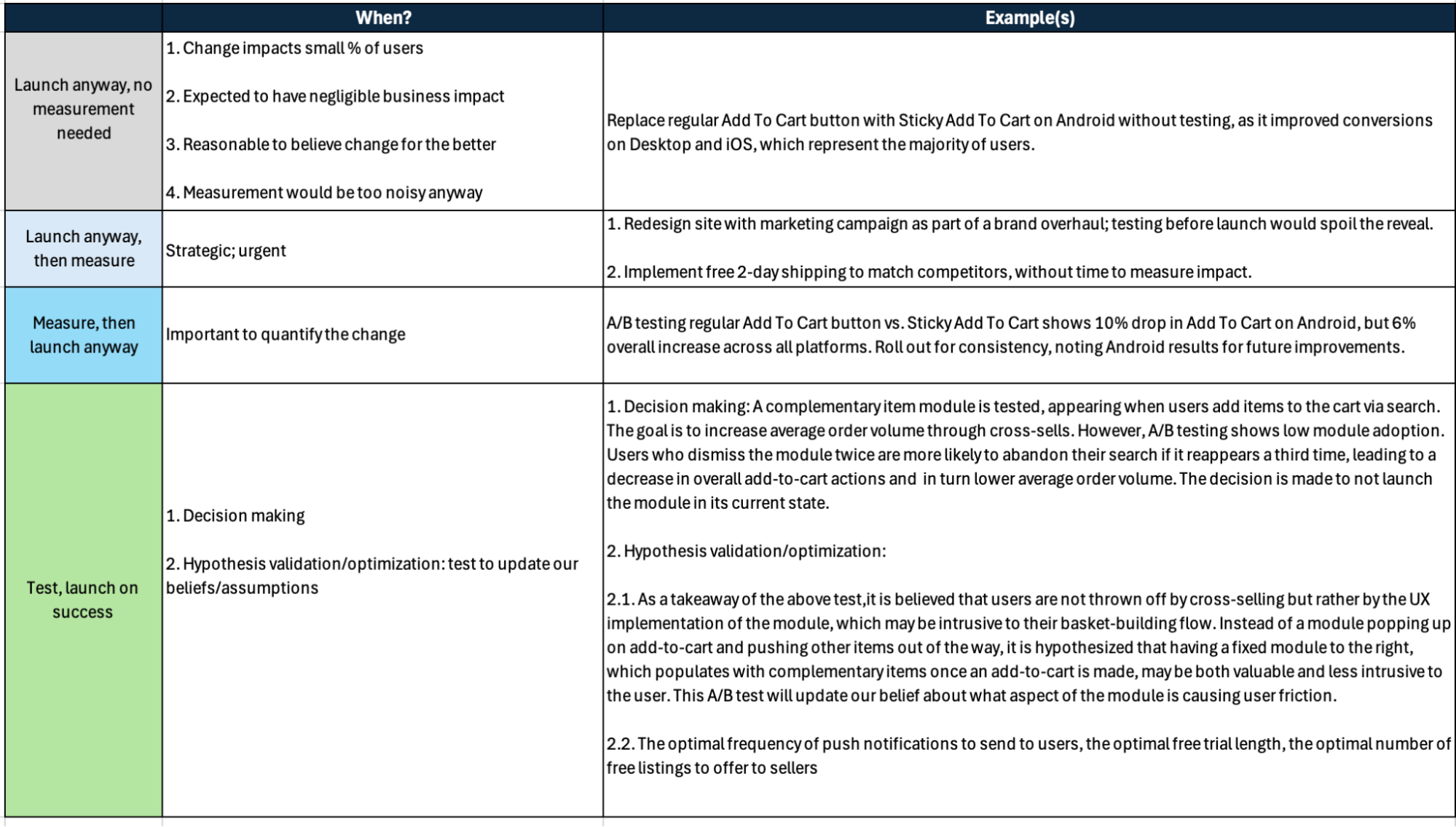
Not all launches can or should be tested or even measured. Before embarking on a test or measurement design, it is essential to ask: Is the change worth measuring, or even measurable? If yes, then given the context, is it possible to measure before launch? If we measure before launch, then A/B testing might be used. Otherwise, a pre-post analysis like Difference-in-Difference or an Event Study may be needed.
In cases requiring pre-post analysis, it is important to be clear on:
- What do we want to measure? 1.a. What can we measure? 1.b. What can we not measure? Why is measurement not possible? What are the implications of the inability to measure?
The questions in 1.b. are important to think through in advance for contingency planning. For example, if a redesigned site launch combined with extensive marketing campaigns leads to year-over-year negative trends, it may not be possible to tell what broke and why. The UX changes could eliminate comparable benchmarks at a granular level, while marketing activities might alter entry points; both UX and marketing can significantly impact user behavior throughout the site.Additionally, pre-post analyses are inherently low-fidelity and, with numerous variables at play, it becomes nearly impossible to isolate the specific causes of these changes.
Even when A/B testing is an option before launch, it is essential to clarify whether the goal is simply to quantify a change or to make a decision. The latter often requires a more complex test design, as it involves more metrics, more segments, additional instrumentation, deeper analysis, and potentially more extensive root cause analysis. This complexity translates into a greater time investment in both test planning and execution.
In any case,any A/B test planning requires addressing the below:
- Defining the success and guardrail metrics we want to measure
- Specifying the amount of change we want to measure for practical significance
- Tabulating the amount of change we can measure with statistical significance given a combination of testing timeline, % of target population addressed and number of metrics to be measured
- Accounting for internal validity risks
- Accounting for external validity risks
- Ensuring Alignment of Analysis Approach and Randomization Unit
- Anticipating deep dive questions to ensure we have the setup needed to answer the critical ones
- Instrumentation (as elaborated in the Event Tracking section)
- The ramp plan and kill criteria; ensuring we are not susceptible to peeking or other p-hacking
The A/B testing considerations are addressed in more details here.
Testing and measurement can be a lengthy process. Some tests may take up to 2 weeks just to finalize planning. While typically the execution of most tests conclude within 2 weeks, there are situations where they need to be run for months.
7. Monitoring -
This involves dedicating time to regularly check dashboards, review reports, or receive notifications about unusual behavior. For example, at eBay and Walmart Labs, we allocated time each morning to review a daily email report summarizing KPIs—covering absolute values, week-over-week, and year-over-year changes, segmented over the past seven days. Monitoring can be conducted at various levels, such as business, product, region, or customer.
In some cases, such as during A/B testing, continuous monitoring is essential to detect potential bugs or issues that could negatively impact the business. Monitoring can also help identify new opportunities or generate hypotheses. For instance, tracking search trends might reveal a sudden increase in demand for a specific category, signaling the need for additional inventory. Alternatively, observing that users on an eCommerce site are favoriting more items and spending more time navigating between product pages could suggest an opportunity to introduce a comparison shopping feature, indicate greater price sensitivity, or highlight interest in a particular product feature. This insight could lead to strategic decisions, such as price adjustments or the use of badges to emphasize key features.
While automated monitoring tools can alert teams to anomalies or when a metric exceeds a specific threshold, there is still significant value in manual monitoring, as it helps build intuition and a deeper understanding of the data.
Analytical Delivery Format
1. Visuals -
Visuals work as a compact and memorable way to represent metrics and trends. Some visuals may serve as the lynchpin of an analysis since they so clearly capture and communicate the main idea. An example of this is the chart for Baumol’s cost disease:
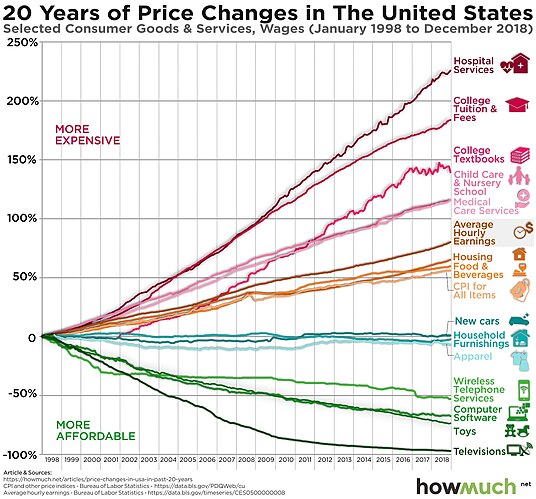
Image Source: Baumol effect - Wikipedia
Depending on the situation, some visuals may be more effective than others. For example, the two charts below illustrate the contribution of various components to the total. However, the top chart—which succinctly shows how a company transitioned from unprofitable to profitable within a year, primarily due to cost reductions in Sales & Marketing (S&M)—is more compact and information-rich compared to the bottom chart:
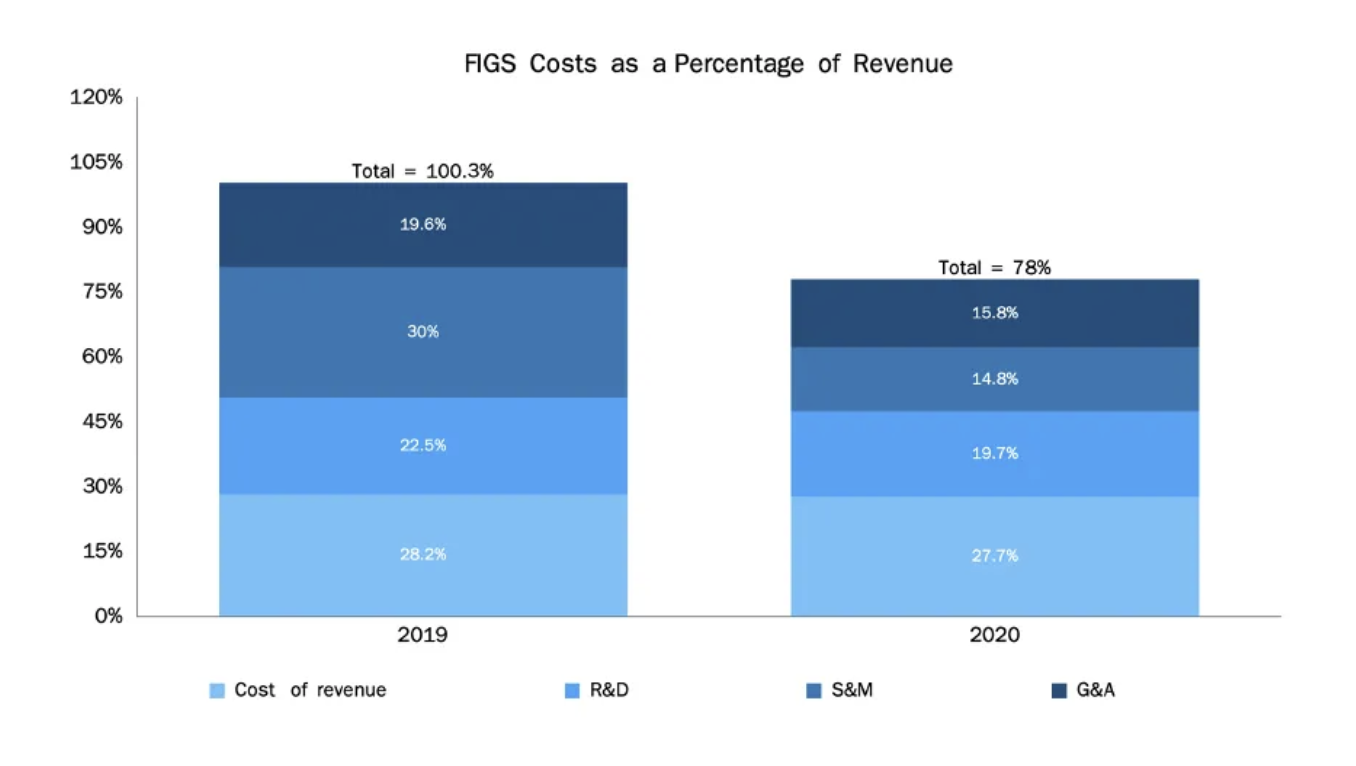
Image Source: FIGs and successful DTC companies
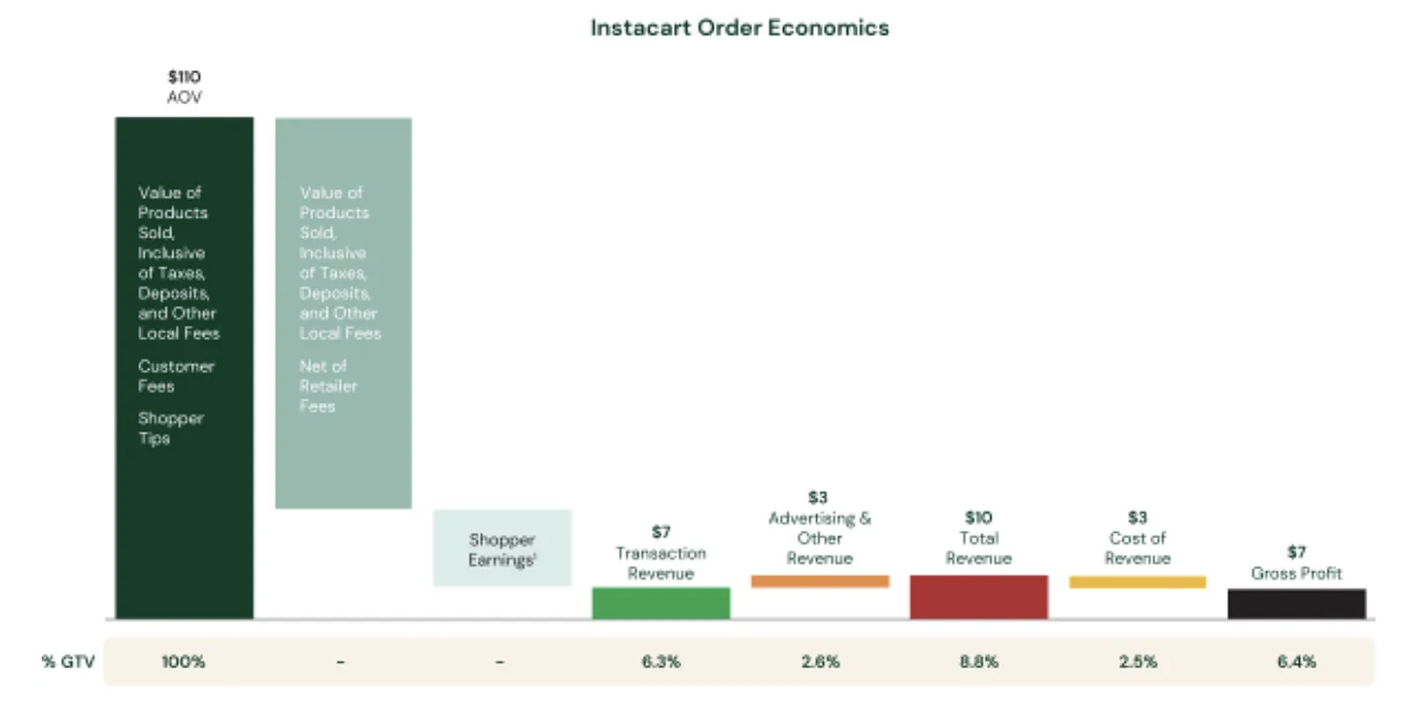
Image Source: Instacart S-1 Breakdown
2. Dashboards -
Unlike one-time analyses, dashboards help maintain a constant pulse on how metrics are tracking against benchmarks. These benchmarks could be a business objective, a forecast, past performance, or other segments. The challenge in building dashboards lies in selecting the right information and presenting it in a concise, insightful, and actionable way.
However, even with the right metrics and data, dashboards can become difficult to use if the correlations and insights are not immediately clear, leaving exploratory analysis to the user. This defeats the purpose of a dashboard, which should enable quick, high-level inferences.
Therefore, when building dashboards, it’s crucial to start by identifying the questions the user needs to answer and the specific patterns they should monitor.
Below is a dashboard view I found particularly effective. It includes a table that outlines where each user dropped off in a funnel. Colors indicate the distance each user progressed in the funnel, with orange representing the most valuable user group. Ideally, the orange bars should be as large as possible, as the goal is to prevent users from getting stuck at “Home.”
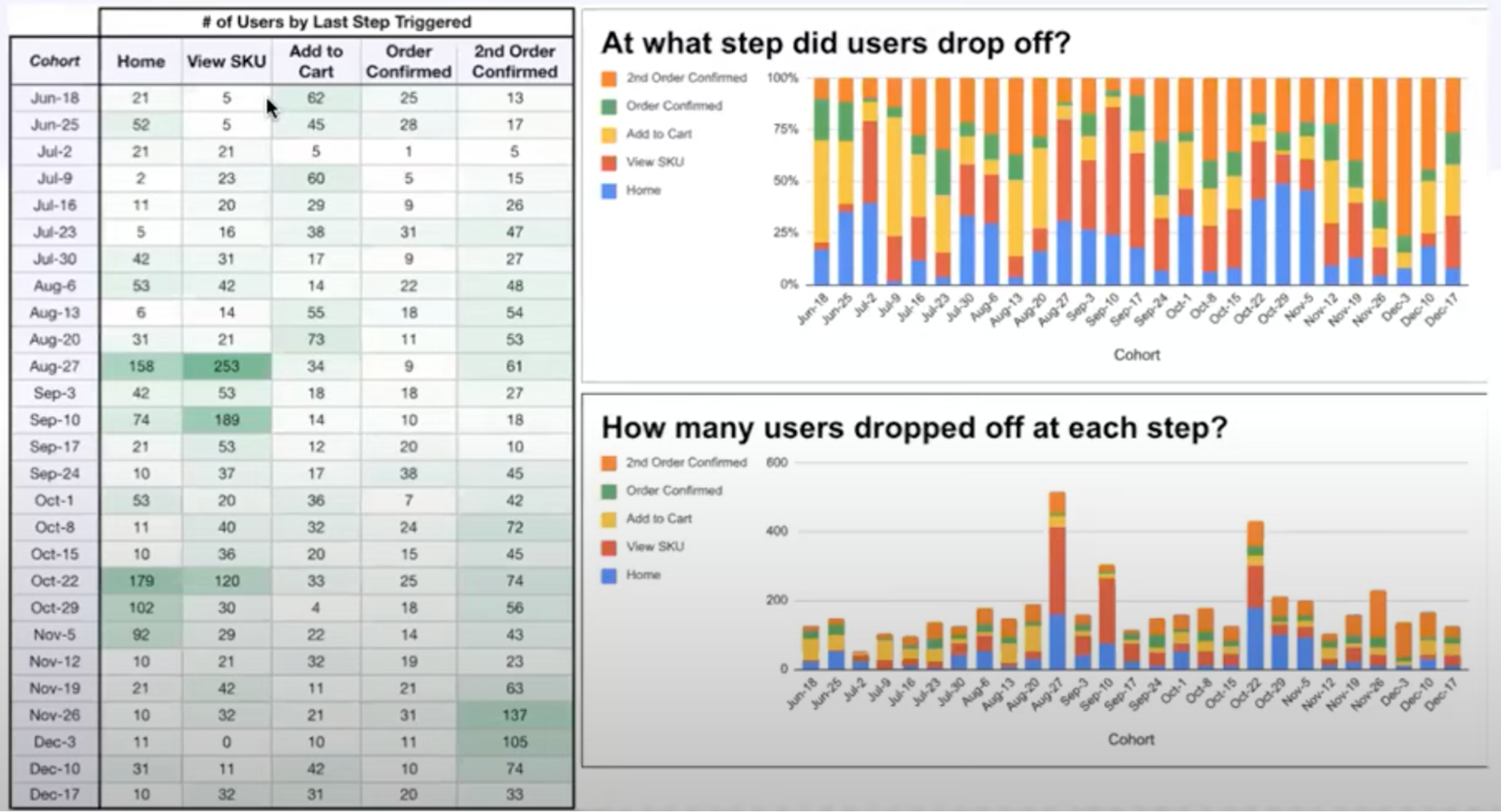
Image Source: A Better Approach to Analyzing Activation Funnels
This view is excellent because, at a glance, it reveals whether the most critical step is improving or deteriorating over time. If our target’s performance declines, it also provides insight into why that happened.
3. Storytelling -
This is essentially a structured account of connected events. One effective approach is to use the Pyramid Principle, where we start with the main insight or takeaway, followed by supporting data, and then drill down into the details if applicable.The storytelling approach depends on the context. One example is Amazon’s 6-pager structure that includes Goals, Tenets, State of the Business, Lessons Learned, and Strategic Priorities. Another 6-pager however starts with a press release, outlines the current state of the business, reviews historical data from the last period, sets goals for the current period, and explains how an executive plans to achieve these goals.A good rule of thumb is to consider the audience’s interest, knowledge, and expectations, and then bridge the gap between that and what we want them to take away from the story. S-1s are essentially data driven storytelling-here are examples from Doordash and Instacart. Blogs such as this one digging into Netflix’s LTV and CAC or this one breaking down the Cash Conversion Cycle are also good examples of analytical storytelling.
4. Standardized reporting -
This includes output that can be templatized for e.g. an A/B test report or scorecards used for weekly business reviews. This falls between a dashboard that allows self-service analytics and an explanatory story, providing a concise snapshot update.
Data Collection and Transformation
1.Event Tracking Specs -
Event tracking involves defining data events and configuring tools to track and collect those events. This process is especially critical when testing a new product or feature but is also valuable for measuring new metrics for an existing feature.
The article Why Most Analytics Efforts Fail provides an in-depth discussion on how to approach tracking and determining what should be tracked. Alternatively, Introduction to Event-Based Analytics offers a concise summary:
- Start with High-Level Core Business Functionality: This should be depicted through user stories and personas.
- Focus on Capturing Success Events: Key events might include signup_completed, payment_submitted, trial_activated, activity_logged, etc. Additionally, track user intent events such as onboarding_started, upsell_view, and recording_start.
- Ignore Granular Activities: Focus on meaningful events that align with business goals.
- Set Initial Activity Events: For example, differentiate between first_app_open vs app_open and first_payment_success vs payment_success. This allows for reporting on new users, returned users, winbacks, and more.
I also appreciate the example of a simple and effective data catalog:

Image Source: Introduction to Event-Based Analytics
The below image is also very helpful in understanding the distinction between events and event properties, as well as the difference between event properties and user properties.
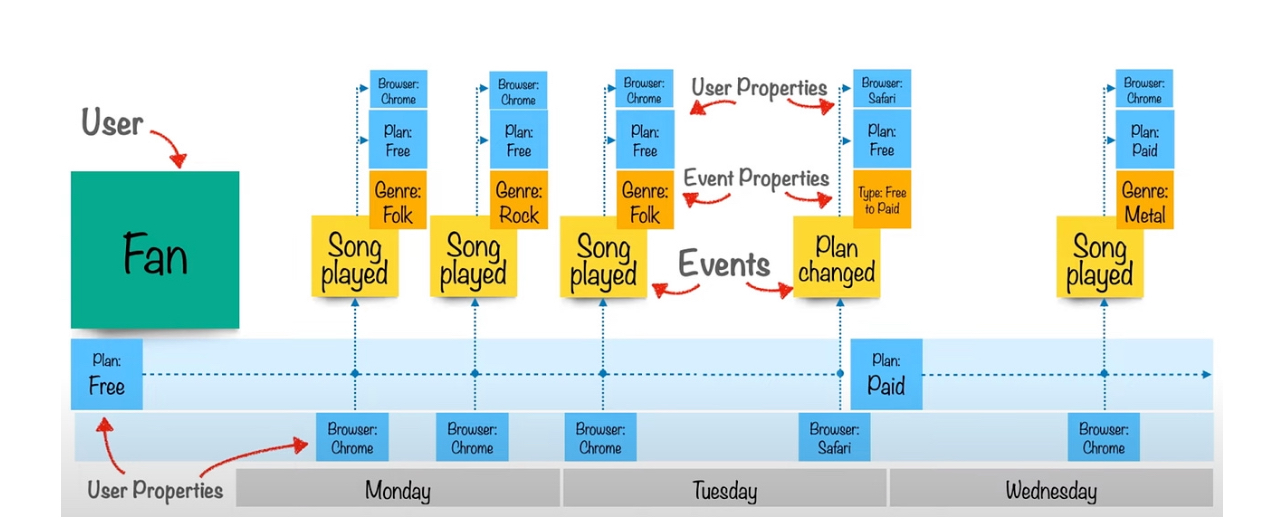
Image Source: Event-Based Analytics
2. Summary Tables -
Summary tables are primarily for the benefit of other analysts and are typically used internally within the Analytics team. They can also be useful for business units (BUs) and product managers (PMs) who need to run quick, simple queries for recurring requests. In these cases, raw data in summary tables can be more valuable than pre-built dashboards.A well-designed summary table simplifies SQL queries and reduces the risk of over-complicating analyses, as highlighted in this post. For domain analysts—such as those focused on search—it’s helpful to have summary tables that are accessible to analysts from other domains, like checkout. This allows them to quickly understand how changes in one domain, like item availability in search, may impact another domain, such as checkout.